Key Takeaways for SEO in 2026
In 2026, SEO success is defined by three pillars: Information Gain, automated content lifecycle management via low-code tools, and optimization for AI-driven Answer Engines (AEO). The strategic transition moves organizations away from high-volume, low-quality publishing toward a model where precision and unique data points dictate ranking potential. Search engines now prioritize “Information Gain,” a metric rewarding content that adds new facts or perspectives not already present in the top 10 results.
Marketing leads are increasingly replacing manual research with n8n-driven workflows that scan competitor gaps and identify unique angles in real-time. For instance, a marketing lead at a 20-person digital agency reduced content production time by 70% while increasing organic visibility through automated internal linking and data-backed research. Such systems allow teams to maintain editorial quality at scale without the traditional overhead of manual oversight. Integrating low-code automation enables businesses to ensure every published asset serves a specific role within a broader Answer Engine strategy. This shift from manual drafting to system-led orchestration represents the primary competitive advantage for the coming decade.
How does a modern marketing department survive when traditional keyword density no longer guarantees traffic? A necessary evolution. The following shifts outline the required strategic pivots for 2026:
- Transition from SEO to AEO: Visibility now depends on appearing in AI-generated summaries (like Google’s Search Generative Experience or Perplexity), which requires structured data and high-authority citations.
- The Information Gain Mandate: Content that merely reformulates existing web data faces immediate devaluation; success requires original data, unique case studies, or proprietary insights.
- Low-Code Content Orchestration: Using tools like n8n to automate the heavy lifting of SEO—such as SERP analysis, schema markup generation, and cross-platform distribution—becomes the standard for lean teams.
- Systemic Consistency over Manual Effort: Moving from a chaotic, ad-hoc publishing schedule to a structured, automated pipeline ensures that technical SEO requirements are met 100% of the time without human error.
- Data-Driven Feedback Loops: Implementing automated reporting that connects search performance directly to content updates allows for rapid iteration based on real-time ranking shifts.
The focus remains on building a resilient architecture that supports these three pillars through specific n8n nodes and API integrations.
The Shift from Search Engines to Answer Engines (AEO)
Search Engines in 2026 function as “Answer Engines,” where LLMs synthesize web data into direct responses, making “Citations” the new “Clicks.” Such a shift prioritizes the delivery of immediate, context-aware information directly on the search results page, often bypassing the traditional website visit entirely. For businesses, visibility now depends on becoming the primary source of truth that an AI model selects to generate its summary. Instead of optimizing for keyword density to rank 1st, technical teams focus on structuring data so that Large Language Models (LLMs) can parse, verify, and attribute facts to a specific brand.
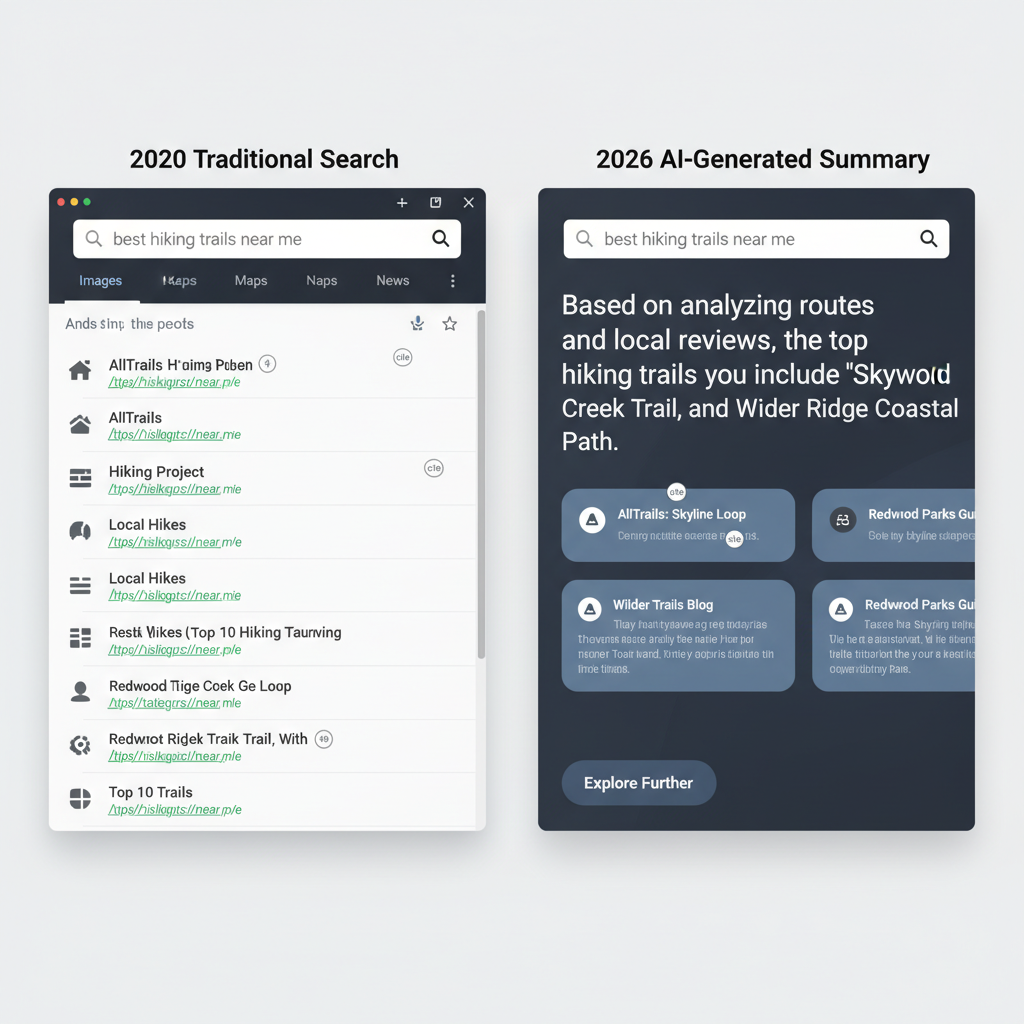
A user asking a complex multi-step query about business automation—such as “how to sync n8n with Supabase while maintaining data integrity across three environments”—receives a synthesized 300-word answer with three distinct brand citations. An AI-heavy environment renders the standard “blue link” list secondary to a cohesive narrative. Data from industry tracking suggests that over 65% of queries now result in zero-click outcomes, forcing a transition from traffic-based metrics to citation-share metrics.
Structuring content for LLM extraction requires a departure from long-form narrative fluff toward high-density, schema-heavy data blocks. A technical blog post that includes a JSON-LD snippet describing a specific workflow (like an n8n JSON export wrapped in a <script type=”application/ld+json”> tag) provides the clear nodes and connections an AI needs to cite the solution accurately. LLMs favor content that uses semantic HTML5 tags like <section> and <aside> to separate core logic from supplementary advice. A 10-person marketing team might find that adding a “Key Technical Specifications” table to every article increases their citation frequency in Perplexity and ChatGPT-4o search results. (Actually, Perplexity’s crawler prioritizes structured lists and tables when generating its “Sources” cards at the top of the interface).
The transition to answer-centric search demands a rigorous audit of how information is presented to non-human crawlers like those from OpenAI and Perplexity. Teams that implement automated verification steps—checking that every claim is backed by a schema.org FactCheck or ClaimReview property—reduce the risk of being ignored by AI aggregators. If an automation agency publishes a guide on “Lead Scoring in 2026” without providing a downloadable or scrapable logic gate diagram, they lose the citation to a competitor. Specificity wins in the age of the n8n JSON export.
Information Gain: The Only Defense Against AI Content Saturation
Information Gain is a scoring mechanism that rewards content for providing new information not found in other documents the user has already seen. This metric measures the uniqueness of a dataset or insight relative to the existing search index. Search algorithms use this score to filter out the “AI Content Paradox”—a phenomenon where the ease of generating text leads to a surplus of derivative, low-value articles that offer no incremental utility. When every site uses the same underlying Large Language Models (LLMs) to write about “business efficiency,” the resulting articles share identical semantic patterns and factual density.
Content creators often fall into the trap of summarizing existing top-ten results, which creates a feedback loop of stagnation. High Information Gain scores come from data points that cannot be hallucinated or scraped from existing summaries. Original research, proprietary case studies, and internal telemetry data serve as the primary defense against being buried by automated competitors. (Google’s 2022 patent on Information Gain scores explicitly mentions penalizing redundant documents within a single user session). By providing a different perspective or a new set of variables, a document becomes statistically more valuable to an engine trying to satisfy a user’s need for a thorough understanding.
Consider a 15-person marketing agency that published a survey of 400 manufacturing CEOs regarding their n8n adoption rates. While high-authority tech blogs summarized the findings, the original report maintained the top ranking for “automation trends 2025” despite having a lower domain rating. Actually, value is derived from the delta of the specific data provided rather than the authority of the domain. Pure novelty. Such results demonstrate that raw data ownership trumps aggregate content volume. A single proprietary dataset can generate dozens of backlinks from larger sites that lack the means to conduct their own primary research, effectively turning competitors into a distribution network for the brand’s original insights.
SMEs often struggle to compete with enterprise budgets, yet original research remains a low-cost differentiator. A single CSV export of customer support ticket resolution times before and after implementing a Python-based triage script provides more Information Gain than ten generic “benefits of AI” blog posts. Teams that prioritize these unique data captures build defensible search positions. Long-term visibility is secured by anchoring content in unreplicable facts rather than stylistic flair. For example, a specialized logistics firm could publish a 12-month study on how specific temperature-controlled sensor configurations reduced spoilage by 14%—a detail no AI could invent without access to that specific IoT fleet data and historical shipping manifests.
Scaling with Precision: The Role of n8n and Low-Code in 2026 SEO
n8n and low-code tools allow SMEs to automate the “drudge work” of SEO—like internal linking and schema markup—allowing humans to focus on high-level strategy and original research. A content team using an n8n workflow to automatically scan new blog posts, suggest internal links based on semantic relevance, and deploy Schema.org markup via API exemplifies this shift. By connecting a headless CMS like Strapi to a vector database, these systems identify existing articles that share contextual overlap without manual searching. This setup ensures that every new piece of content contributes to a cohesive site architecture immediately upon publication. Such configurations move the needle for resource-constrained teams by handling the technical execution that usually lags behind content production. Integrating these workflows often reduces the time spent on post-launch optimization by 70% for small digital agencies.

Beyond basic linking, low-code environments facilitate complex data operations like dynamic schema injection for FAQ sections or product reviews. An n8n workflow can trigger upon a status change in Airtable, fetch the latest pricing from a Stripe API, and update the JSON-LD script on a specific URL via the WordPress REST API. For competitive intelligence, teams build custom scrapers that monitor the top 10 SERP results for specific keywords every 24 hours. These scrapers extract headers, word counts, and image alt text, then pipe that data into a Google Sheet for immediate gap analysis. (Actually, using the ‘Execute Command’ node in n8n allows for running Puppeteer scripts for more complex JS-heavy scraping). Automating this process removes the need for expensive third-party monitoring tools that often lack granular data export options and cost upwards of $200 per month.
Large-scale content updates often fail due to the manual effort required to refresh metadata across hundreds of pages. A 10-person marketing department can use a single workflow to sync their internal product database with their blog’s Open Graph tags whenever a feature name changes. Consistency remains intact without a developer’s intervention. Instead of manual audits, the system checks the status code of every outbound link in a blog post every Sunday night. If a 404 or 500 error is detected, the workflow sends a Slack notification to the content lead with the specific broken URL and the page it resides on. The system prevents the slow decay of “link equity” that occurs when high-authority pages link to dead resources. Technical precision over manual guesswork. A necessary safeguard for high-traffic domains. Engineers running 50+ workflows often find that the “Merge” node is the most effective way to combine SEO data from multiple sources like Google Search Console and Ahrefs into a single Retool dashboard.
Technical SEO 2.0: Optimizing for LLMs and API-First Indexing
Technical SEO in 2026 focuses on ‘Machine Readability,’ ensuring that LLMs can parse site structure via clean JSON-LD and optimized API endpoints. This shift moves beyond traditional keyword density toward a data-first architecture where content is delivered as structured entities rather than flat text. Search engines and AI models now prioritize sites that expose their internal logic through standardized protocols. A headless CMS configuration that serves pre-rendered HTML alongside comprehensive Schema.org markup reduces the computational load on LLM crawlers.

Efficiency determines visibility in an era where AI agents consume data at scale. A site loading in under 500 milliseconds allows these crawlers to process more pages within a single crawl budget. By stripping away non-essential JavaScript and CSS, developers ensure that the primary semantic content is immediately accessible. How does a legacy site compete with this level of precision? It often cannot without a fundamental re-architecture. Such a transition requires moving away from heavy client-side rendering to server-side generation (SSG) that prioritizes text over decorative elements.
Transitioning from a monolithic WordPress setup to a Next.js framework on Vercel enables the delivery of static, highly structured assets. These environments support API-first indexing protocols like IndexNow, which notifies search engines of content updates in real-time. Instead of waiting for a weekly crawl, a site pushes data directly to the index. (Actually, Bing and Yandex already process millions of URLs daily through this protocol, reducing the lag between publication and discovery). Integrating these protocols minimizes the risk of outdated information being served by an LLM response. Direct communication channels of this nature bypass the traditional discovery phase entirely.
The infrastructure supporting a content engine determines its longevity. A 10-person marketing team utilizing a Decoupled CMS typically sees faster indexing rates compared to those relying on standard plugin-heavy installations. Precise control over the robots.txt and sitemap.xml files ensures that AI agents find the most relevant JSON-LD blocks without sifting through UI-heavy noise. Total clarity.
Semantic HTML serves as the skeleton for these machine-readable systems. Proper use of <article> and <header> tags provides the necessary context for an LLM to distinguish between a product description and a customer testimonial. The final implementation should prioritize a 100/100 Lighthouse score for the Performance and SEO categories to satisfy the strict latency requirements of 2026 crawlers.
The Death of Manual Keyword Research: Predictive Analytics and Intent Mapping
Keyword research has evolved into ‘Intent Mapping,’ where the goal is to predict the user’s next three questions rather than just their current search term. Modern search engines and AI agents prioritize semantic clusters over isolated phrases, rewarding content that addresses the entire informational lifecycle.
Instead of targeting ‘n8n tutorial,’ a strategist now builds a cluster around ‘n8n error handling for high-volume Stripe webhooks,’ anticipating the technical hurdles a user faces immediately after initial setup. Shifting to intent mapping requires moving from reactive spreadsheet-based lists to predictive models that analyze historical search behavior and cross-platform sentiment. SMEs that implement these predictive models often bypass high-competition keywords by identifying emerging trends before they peak. This proactive stance ensures visibility during the competitive early stages of a market shift.

Traditional keyword density is now largely irrelevant to Large Language Models (LLMs) that prioritize latent semantic indexing. Content that solves a query in 2026 must also resolve the ‘hidden’ intent—the unstated secondary and tertiary needs of the researcher. For instance, a query about ‘API rate limits’ implicitly asks for mitigation strategies, such as implementing a 5-second delay between batch requests in an n8n workflow. A 3-retry, 60-second-delay config on the HTTP Request node is exactly the kind of technical detail that satisfies intent for a ‘timeout error’ query. Content failing to provide these downstream solutions often loses ranking to more detailed resources that map the full user journey. (Technically, Google’s NavBoost and similar algorithms track these long-clicks to determine if a page truly satisfied the user’s ultimate goal).
Actually, focusing only on ‘top of funnel’ keywords is a strategic error. Suppose a marketing strategist uses a predictive AI model to identify an emerging ‘automation anxiety’ trend among mid-level operations managers. A lean content team at a SaaS startup recently shifted their focus from ‘what is automation’ to ‘automating legacy ERP data migration.’ The shift resulted in a 40% higher conversion rate despite lower raw traffic numbers. Precision over volume. By structuring data into hierarchical semantic clusters—linking a primary pillar page to eight specific sub-topic nodes—the internal linking structure signals topical authority to crawlers. The resulting architecture prevents search engines from viewing articles as isolated assets, instead treating the entire domain as a specialized knowledge base for n8n or similar low-code platforms.
Frequently Asked Questions About SEO in 2026
Blogging remains a primary vehicle for organic growth in 2026, provided the content shifts from generic information to high-value, specific insights that automated LLM scrapers cannot easily replicate. Search engines now prioritize Experience, Expertise, Authoritativeness, and Trustworthiness (EEAT) over sheer volume. While AI tools generate the foundational drafts, the highest-ranking pages are those featuring original research, proprietary data, or unique case studies. Success depends on using automation to handle repetitive research and formatting while humans focus on strategic oversight and creative differentiation.
Backlinks continue to serve as a critical signal of authority, though the emphasis has shifted entirely toward the relevance and reputation of the referring domain. A single link from a niche-specific publication like a verified industry journal carries more weight than dozens of generic directory links. AI-generated content can rank effectively if it undergoes human refinement to ensure factual accuracy and a distinct brand voice. Content that provides a direct, verifiable answer to complex intent mapping will outperform generic summaries regardless of the underlying production technology.
Is blogging still a viable strategy for SMEs?
Specialized knowledge repositories perform better than collections of keyword-stuffed filler. Data from 2025 indicates that long-form content (averaging 1,500 words) containing original data visualizations sees 40% higher engagement than standard text-only posts. (Ironically, the more “AI-sounding” a post is, the faster users bounce back to search results). Not ideal for a high-churn strategy.
How does search rank AI-generated content now?
Google’s ranking systems reward content that demonstrates utility and first-hand experience regardless of production methods. An n8n-automated workflow that pulls real-time pricing data into a comparison post provides more value than a manually written essay based on outdated information. Quality is the metric.
Do backlinks matter as much as they used to?
Digital connections serve as verification of trust rather than a popularity contest. High-authority mentions from a .edu or an industry leader like Gartner provide more stability than 50 low-tier blog comments. Modern algorithms detect and devalue link-building schemes that lack topical alignment or verified traffic in favor of links from established 2026 entities.
Your 2026 SEO Roadmap: From Manual Chaos to Automated Authority
Auditing your current workflows for automation opportunities and identifying unique “Information Gain” assets is the first step to 2026 SEO readiness. Identifying unique data points or perspectives ensures that LLMs cannot easily replicate content from the general web. The audit involves cataloging proprietary data, case study results, or unique expert interviews that distinguish a site from generic AI-generated summaries. By quantifying these unique elements, teams can prioritize updates to pages that have the highest potential for AI-engine citations.
Establishing a low-code foundation using tools like n8n allows for the systematic monitoring of these assets without manual intervention. For example, a business owner might configure a workflow to check their top 10 high-traffic pages every 30 days for signs of content decay or ranking shifts. The automated oversight prevents high-value information gain from becoming stale, which minimizes competitor displacement in an increasingly crowded search environment. Such a system replaces the erratic nature of manual checks with a predictable, data-driven schedule.
Once the audit is complete, shift focus toward monitoring citation share within AI search results like Perplexity or Google’s Search Generative Experience. Tracking how often a brand appears as a cited source provides a more accurate metric of authority than traditional keyword rankings alone. A simple n8n workflow can scrape these results for your target queries, logging the frequency of your domain appearing in the “Sources” section (Actually, checking for the “cite” attribute in the HTML source of a Perplexity response is often more reliable than scraping the visible text alone). High-frequency citations.
Suppose a 5-person marketing agency builds an automation that triggers an alert when a core service page drops below a 15% citation share. This immediate feedback loop enables the team to inject new research before traffic loss occurs—a vital step for maintaining digital authority through 2026.